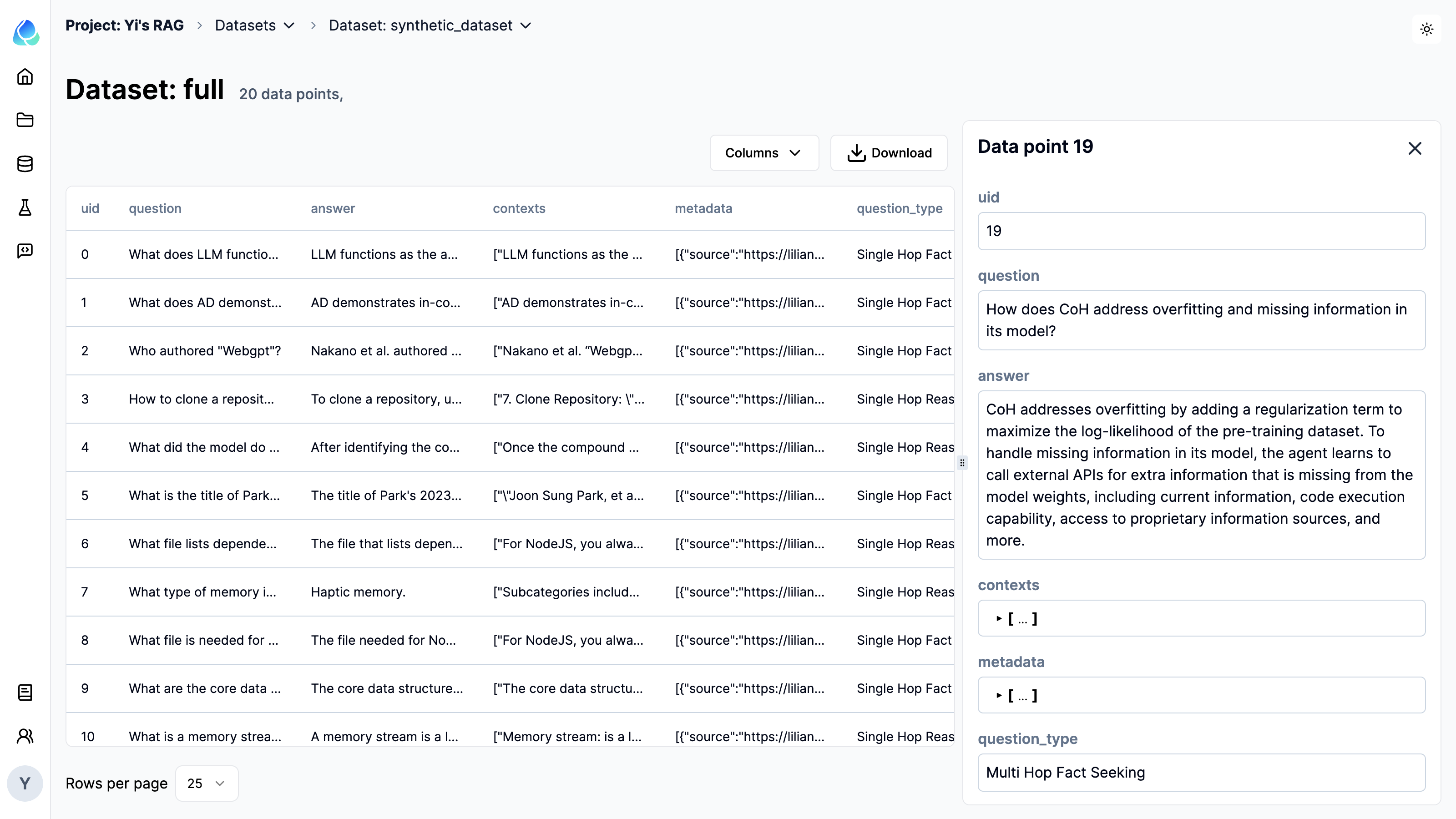
Generate synthetic datasets
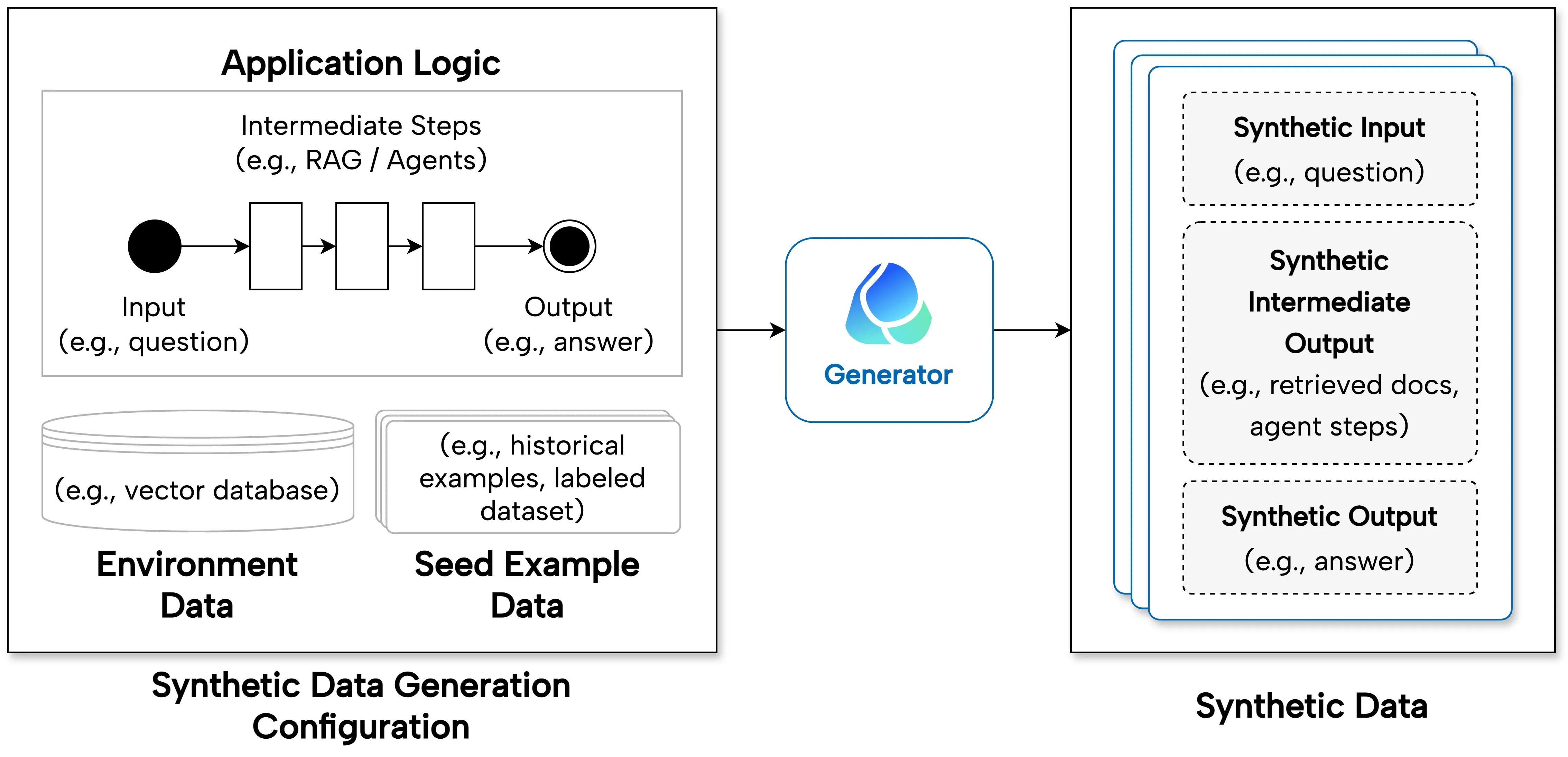
Architecture of Synthetic Data Generation Pipeline
Here's the high level flow to generate the synthetic datasets. We will use your existing application logic and optionally environment data and seed example data to create the synthetic inputs and expected outputs (both intermediate and final).
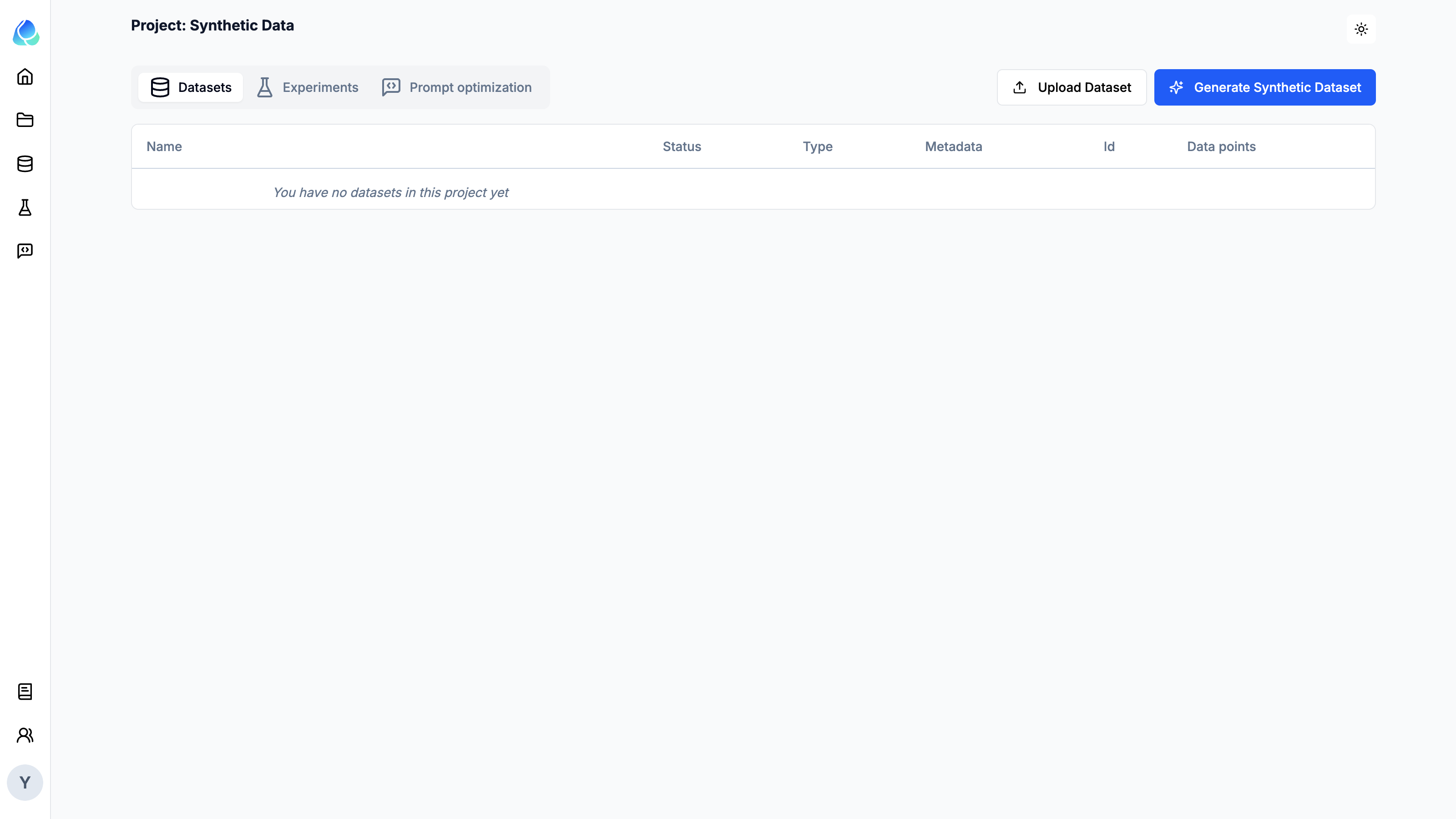
Navigate to the Datasets tab in the project and click on the Generate Synthetic Dataset button to start the process.
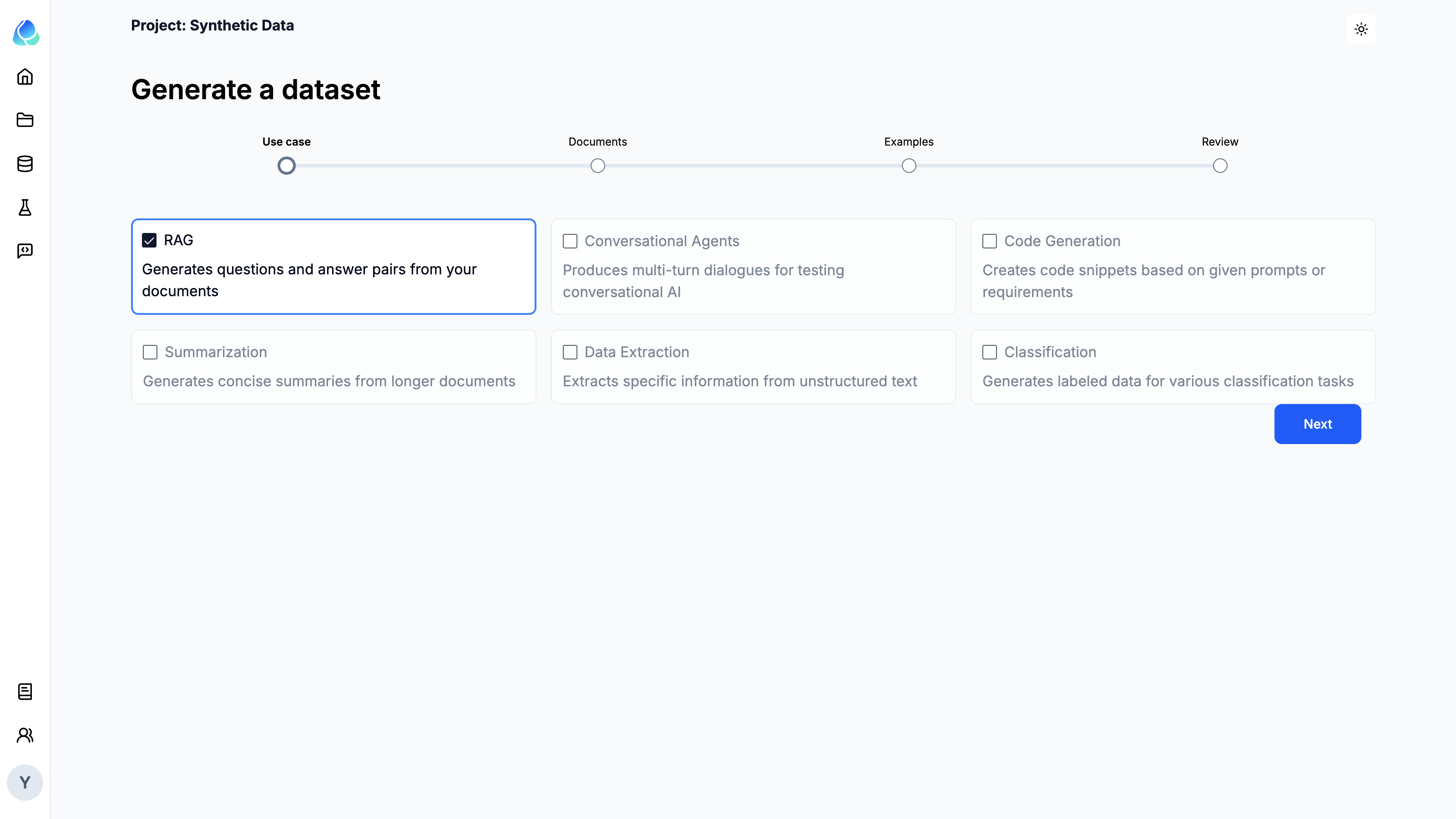
Step 1: Define the use case application logic
Define the use case application logic by selecting a common LLM application logic. You can define custom application logic by selecting the Custom option in the enterprise version.
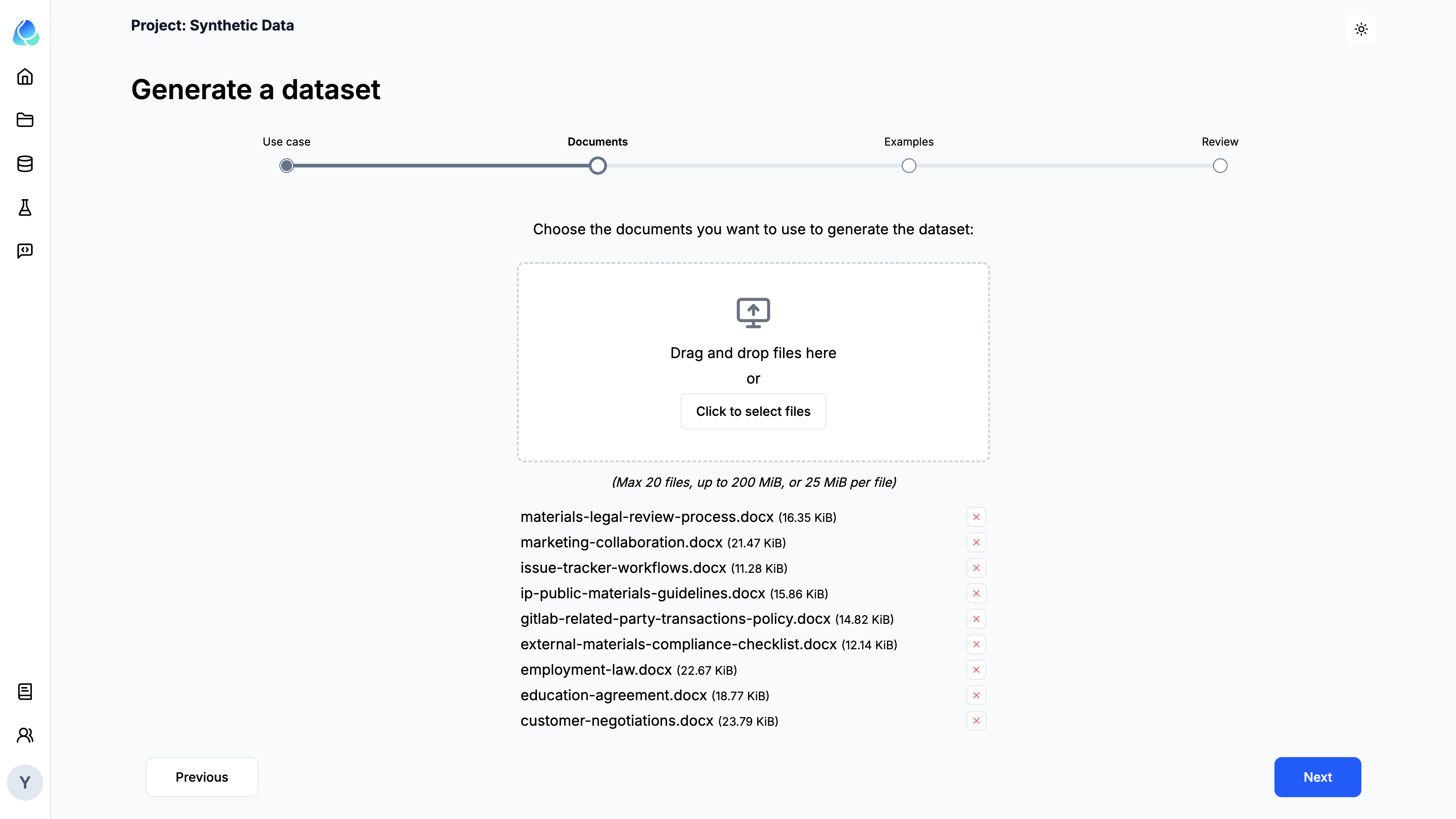
Step 2: Define the environment data
Define the environment data by specifying the contextual information and parameters that will influence the generated dataset.
Step 3: Seed example data (optional)
Provide initial samples (Inputs and/or Expected Outputs) that will serve as a foundation for generating more extensive synthetic data.
Step 4: Generate synthetic data
Submit to the Relari Cloud for generation. You will get an email notification once the synthetic data is ready.