Why use datasets?
Data can be your secret weapon to make your AI app stand out. Leveraging use-case-specific data helps you understand your app's performance better, automate parts of the iteration process, and make your application more reliable.
Using data throughout your development—from early experiments to after launch—lets you make confident decisions and boosts user satisfaction.
Dataset for Evaluation
Relari allows you to can run evaluation with or without a golden dataset. Here are the pros and cons of each approach:
Data-free evaluation
Data-free (aka reference-free) evaluation means that you are assesssing purely based on the inputs & outputs you have at hand. For example, you can directly compare the question and answer and assess if the answer is directly addressing the question (answer_relevance).
They are the easiest to get started but only offers partial and often inconsistent insights into pipeline.
Data-based evaluation
Data-based (aka reference-based or golden-dataset-based) evaluation means that you are evaluating against a benchmark or expected output. For example, you can compare the answer and the expected_answer and assess if the answer is correct given the expected_answer (answer_correctness).
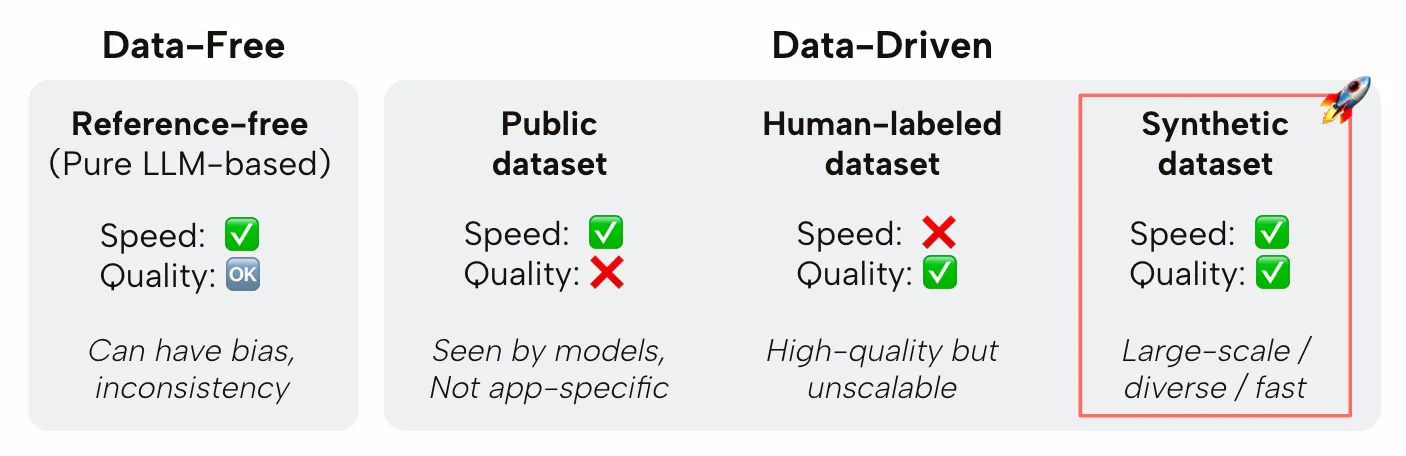
Public datasets
Public datasets include the popular benchmarks you hear about whenever a new LLM is released such as MMLU, HelloSwag, TruthfulQA, HumanEval, etc. While these benchmarks are great for comparing models at a high level, they may not be the best for evaluating your specific use case. Plus because the datasets are public, they are often overfit to by the models they are meant to evaluate.
Human-labeled datasets
Human-labeled datasets are datasets that are labeled by the users or domain experts of your application. These datasets are great for evaluating your model on your specific use case. However, they can be expensive and time-consuming to create. Another downside is usually they lack the granularity needed to evaluate each component of an LLM pipeline. For example, a labeler of a RAG system may be able to provide the right answer to a question, but may not be able to label all the relevant passages that the RAG system should retrieve.
Synthetic datasets
Synthetic datasets is a middle ground that balances ease to get started and quality at scale. You can generate a synthetic dataset from scratch and use them as a starting point. Or they can be used to augment existing human-labeled datasets to provide more comprehensive and granular insights into the performance of an LLM application.
In these blog posts, we go into more details of the pros and cons of each approach and a case study.
- How Important is a Golden Dataset for LLM Evaluation?
- Case Study: Reference-free vs Reference-based evaluation of RAG pipeline
Dataset for Optimization
Golden datasets can also be leveraged to improve components of your LLM application. Here are some ways you can use datasets for optimization:
Auto prompt optimization
If you have a good golden dataset of inputs and their expected outputs, you can use them to automatically optimize your prompts to capture nuanced requirements. Saving you many hours of many hours of manual trial and error. Check out Auto Prompt Optimization for more details.
Systematic LLM fine-tuning
In order to fine-tune an LLM, you need provide a dataset to get started. The arts of fine-tuning is providing the right amount of data with the right level of diversity and scale to make sure the fine-tuned model performs well on the targeted use case. We offer a service to help you fine-tune your LLMs with the right dataset. Please reach out if you'd like to learn more.